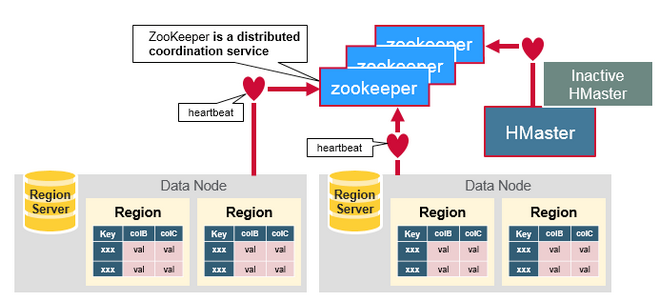
HBase 架构
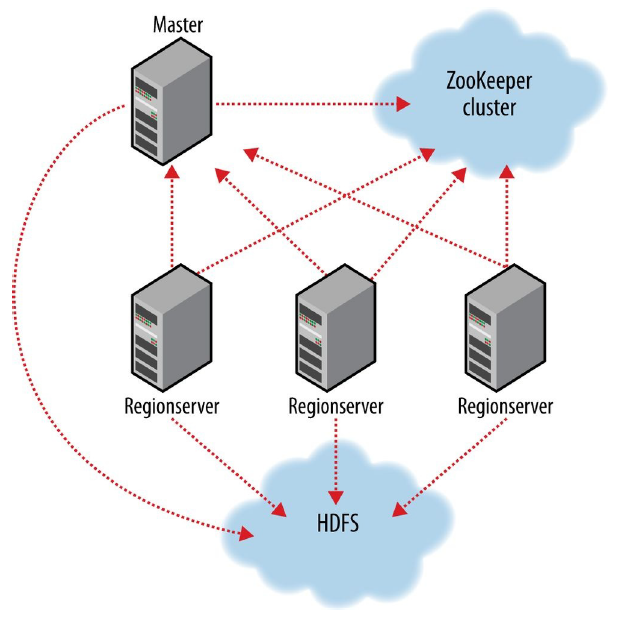
和 HDFS、YARN 一样,HBase 也采用 master / slave 架构:
- HBase 有一个 master 节点。master 节点负责将区域(region)分配给 region 节点;恢复 region 节点的故障。
- HBase 有多个 region 节点。region 节点负责零个或多个区域(region)的管理并相应客户端的读写请求。region 节点还负责区域的划分并通知 master 节点有了新的子区域。
- 客户端获取数据是直连 RegionServer 的,所以当 Master 挂掉之后,还是可以获取数据,但是不能创建表了。
- RegionServer 的数据直接保存在 HDFS 上
- Zookeeper 管理所有 RegionServer 的信息,包括具体的数据段存放的 RegionServer.
- HBase 依赖 ZooKeeper 来实现故障恢复。
Region
HBase 表按行键范围水平自动划分为区域(region)。每个区域由表中行的子集构成。每个区域由它所属的表、它所含的第一行及最后一行来表示。
- Region只不过是表被拆分,并分布在区域服务器。
- region 不能跨服务器,当数据量很小时,一个 Region 会存储所有数据;当数据量很大,HBase 则会拆分 Region
- HBase 在负载均衡时,会将一个 RegionServer 上的 Region 移动到另一台 RegionServer
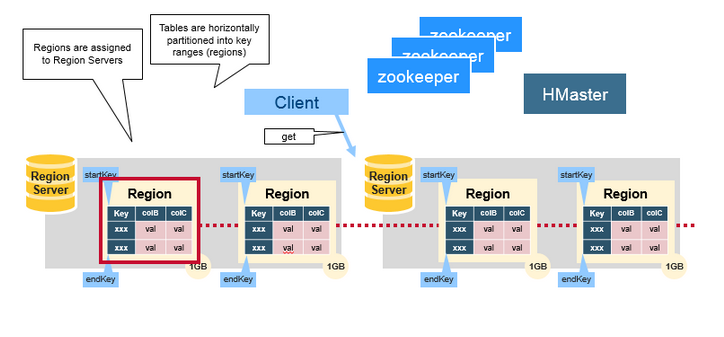
Master 服务器
区域分配、DDL(create、delete)操作由 HBase master 服务器处理。
- master 服务器负责协调 region 服务器
- 协助区域启动,出现故障恢复或负载均衡情况时,重新分配 region 服务器
- 监控集群中的所有 region 服务器
- 支持 DDL 接口(创建、删除、更新表)
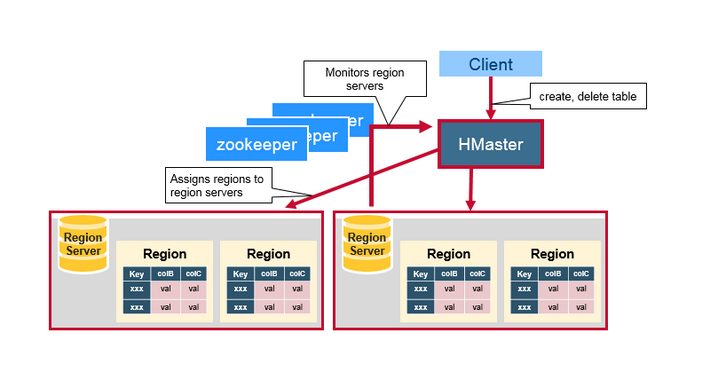
Regin Server
区域服务器运行在 HDFS 数据节点上,具有以下组件
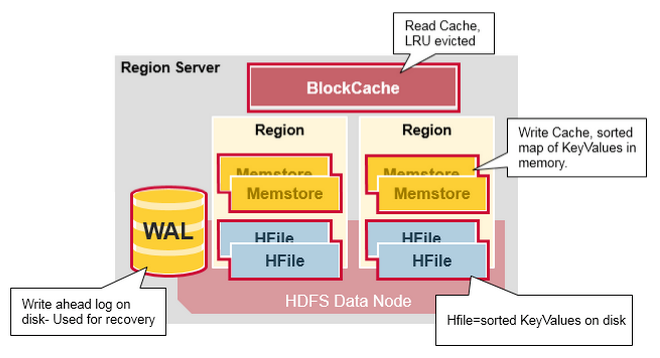
WAL- Write Ahead Log 是 HDFS 上的文件。WAL 存储尚未持久存储到永久存储的新数据,它用于在发生故障时进行恢复。BlockCache- 是读缓存。它将频繁读取的数据存储在内存中。至少最近使用的数据在完整时被逐出。MemStore- 是写缓存。它存储尚未写入磁盘的新数据。在写入磁盘之前对其进行排序。每个区域每个列族有一个 MemStore。Hfiles- 将行存储为磁盘上的排序键值对。
ZooKeeper
HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。Zookeeper 维护哪些服务器是活动的和可用的,并提供服务器故障通知。集群至少应该有 3 个节点。
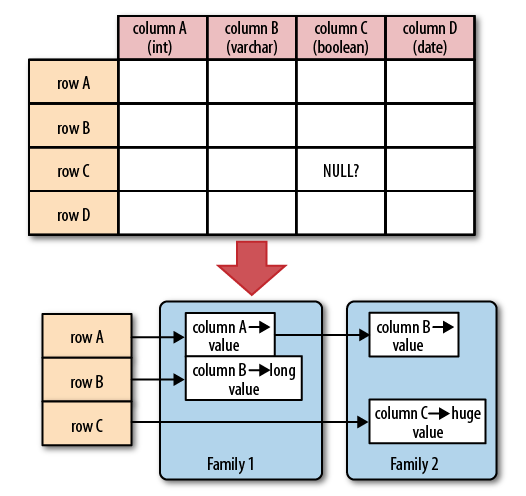
数据模型
HBase 是一个面向列的数据库,在表中它由行排序。
HBase 表模型结构为:
- 表(table)是行的集合。
- 行(row)是列族的集合。
- 列族(column family)是列的集合。
- 列(row)是键值对的集合。
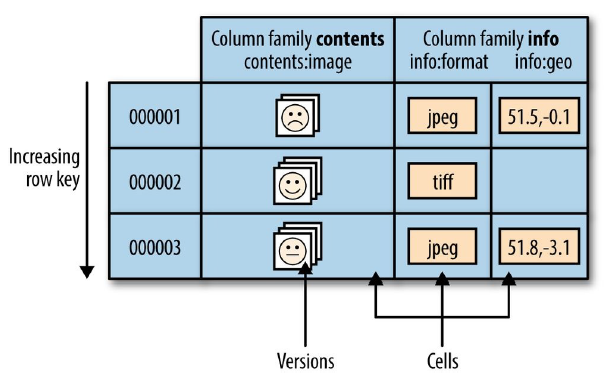
HBase 表的单元格(cell)由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为 HBase 插入单元格时的时间戳。
每个行(row)都拥有唯一的行键(row key)来标定这个行的唯一性。每个列都有多个版本,每个版本的值存储在单元格(cell)中。
HBase 是根据 rowkey 来排序的,所以在定一个rowkey的时候需要尽量将其打散,一个常用的方法就是将原选的ID倒叙。
列族:HBase 会讲相同列族的列尽量放在同一台机器上。
维护工具管理
均衡器
移动 Region 到不同的 RegionServer 上以平摊压力
StochasticLoadBalancer 考虑的因素:
Region Load: Region 的负载Table Load: 表的负载Data Locality: 数据本地化Memstore Szie: 存储在内存中的大小Storefile Size: 存储在磁盘上的大小
与均衡器相关的参数
hbase.balancer.period: 执行周期,默认5分钟。hbase.regions.slop: 均衡容忍值,默认为 0.001。hbase.master.loadbalancer.class: 均衡器实现类
规整器
通过合并或者拆分的手段,将 Region 的大小控制在一个相对稳定的范围内。
具体的实现步骤:
- 获取该表所有的 Region
- 计算该表 Region 平均大小
- 如果某个 Region 大于平均大小的两倍,则需要拆分
- 不管合并最小的两个 Region,只要最小的两个 Region 大小之和小于 Region 平均大小,则就会合并
- 空 Region(小于1MB)不参与合并
拆分/合并风暴:在某种情况下,拆分了几个 Region 后,系统达到了某个阈值,该阈值会触发 Region 的合并,于是开始合并,合并后又触发了另一个阈值,导致 Region开始拆分。
可能影响的因素:
- 均衡器定义的
hbase.regions.slop偏移量 - 拆分 Region 的策略定义
hbase.regionserver.region.split.policy - 单个 Region 下最大文件大小
hbase.hregion.max.filesize
拆分策略
ConstantSizeRegionSplitPolicy:单个 Region 大小超过 10G ,则拆分,目前不用了IncreasingToUpperBoundRegionSplitPolicy:默认,限制不断增长的文件尺寸的策略。计算公式为min(tableRegionCount ^ 3 * intialSize, defaultRegionMaxFileSize)tableRegionCount:表在所有 RegionServer 上所拥有的 Region 数量总和initialSize:默认使用hbase.increasing.policy.initial.size,否则使用hbase.hregion.memstore.flush.size * 2defaultRegionMaxFileSize:hbase.hregion.max.fileeize即 Region 最大大小。
KeyPrefixRegionSplitPolicy:按照keyPrefixRegionSplitPolicy.prefix_length所定义的长度截取 rowkey 作为分组的依据,同一组的数据不会被划分到不同的 Region 上DelimitedKeyPrefixRegionSplitPolicy:同上,但是是根据分隔符来判断的。BusyRegionSplitPolicy:根据 rowkey 热点来分割数据hbase.busy.policy.blickedRequests: 请求阻塞率,默认为0.2,即20%的请求被阻塞。hbase.busy.policy.minAge:拆分最小年龄,小于该年龄的数据不会被拆分,默认10分钟。hbase.busy.policy.aggWindow:计算是否繁忙的时间窗口,默认5分钟。
DisabledRegionSplitPolicy:不拆分,用户自己拆分。
预拆分和强拆分
1 | hbase org.apache.hadoop.hbase.util.RegionSplitter tablename HexStringSplit -c 10 -f mycf |
tablename: 需要拆分的表名HexStringSplit: 指定拆分算法-c: 要拆分 Region 数量-f: 要建立的列族名称HexStringSplit: 将数据从 00000000 到 FFFFFFFF 之间的数据长度按照n等分之后算出每一段的起始 rowkey 和结束 rowkey,以此作为拆分点。UniformSplit:起始 rowkey 是ArrayUtils.EMPTY_BYTE_ARRAY,结束 rowkey 是new byte[]{xFF, xFF, xFF, xFF, xFF, xFF, xFF, xFF}
合并
删除大量的数据之后,每个 Region 都变小了,需要合并。
1 | habse> merge_region 'rowkey1','rowkey2' |
目录管理器
hbase:meta 表中存储的 Region 信息。

